Autoscaling Heroku: The Ultimate Guide

Jon Sully
@jon-sullySo you’ve got your app up and running on Heroku, your web dynos are happily serving requests, and everything is smooth. Traffic is growing steadily, your SEO juice is increasing, sales seem to be on the up and up! But eventually the alerts begin. You’ve got too much traffic for your dynos to handle 😱. Requests are taking too long; some are outright failing. The app is on fire!
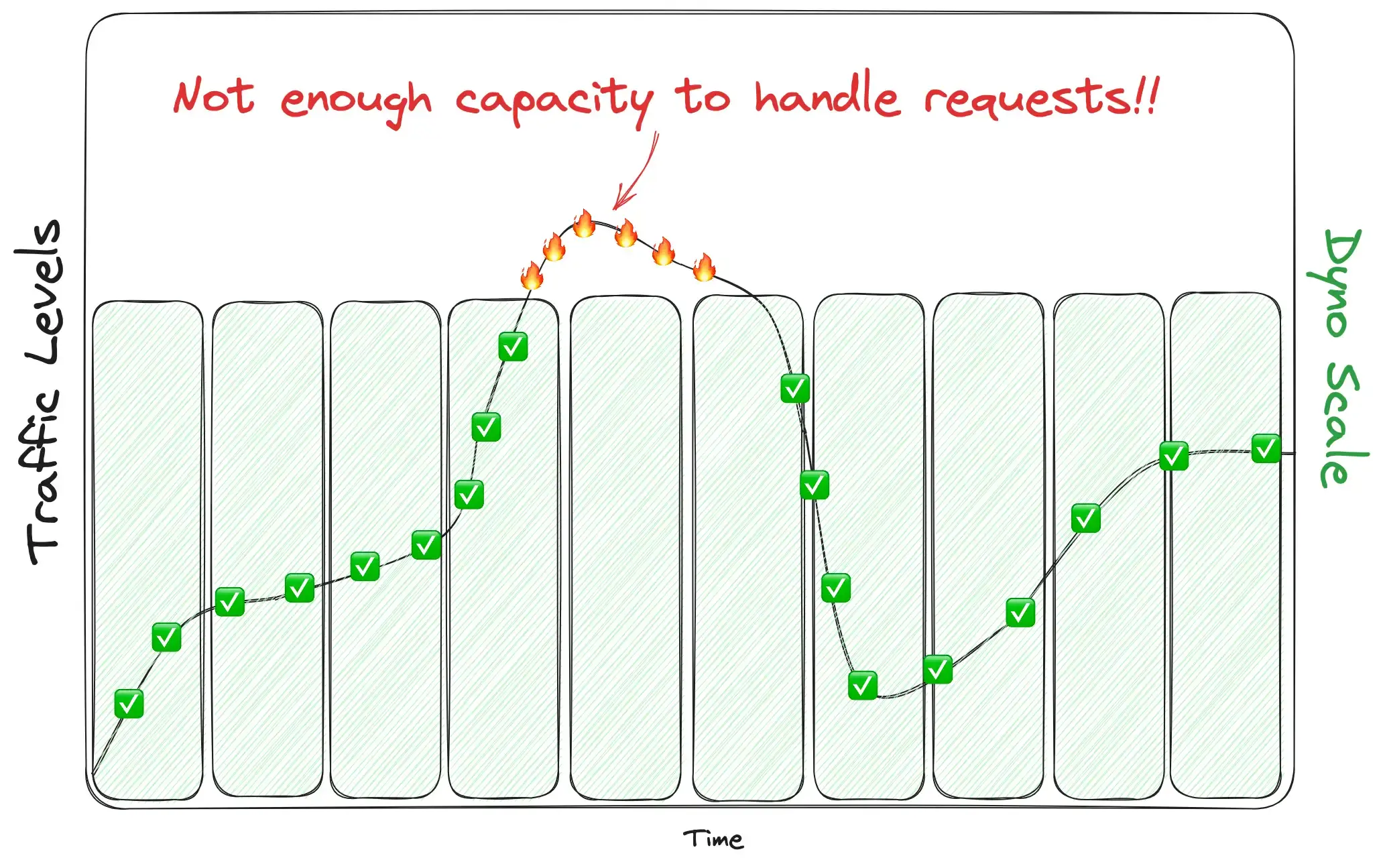

What now? You’ve got options.
Option 1: Throw Money at it
Before we get into automatic scaling, there’s always the “throw money at it” approach. And there are times when throwing money at a problem really is the best solution for the team. Granted, that’s often short-lived, but it’s worth briefly covering. When we say “throw money at it” in this context, we mean to manually set your Heroku dyno count beyond what’s currently necessary to avoid traffic-related issues on your app. We call this over-provisioning: to have a higher number of dynos than necessary for your current traffic level. This is referred to as throwing money at the problem because it’s expensive! Setting your app to run on more-than-necessary numbers of dynos costs... more than what’s necessary 😉.
The Pros
- It’s super easy
- It usually works for some amount of time
- It can temporarily fix some traffic-related issues
The Cons
- It’s risky: you don’t know when your next traffic spike will require capacity beyond what you’ve now hard-coded, even if that capacity level feels quite high right now. Your future traffic levels are a risk
- It’s expensive: as mentioned, this approach wastes money — another form of risk depending on your business and revenue structure
- It doesn’t fix all scale-related issues: for example, if your problem is that your DB has run out of available connections for the dynos you’re already running, scaling up more dynos is only going to make that worse
- It can bite you later: manual over-provisioning can mask potential scaling issues that could rear their heads at the worst moment
Let’s take a look at this approach in a more visual manner. Here we plot example traffic levels (black line) against dyno scale levels (green boxes). Since we’ve set a hard-coded, high number of dynos, all of the green boxes are tall and constant over time — our scale never changes.
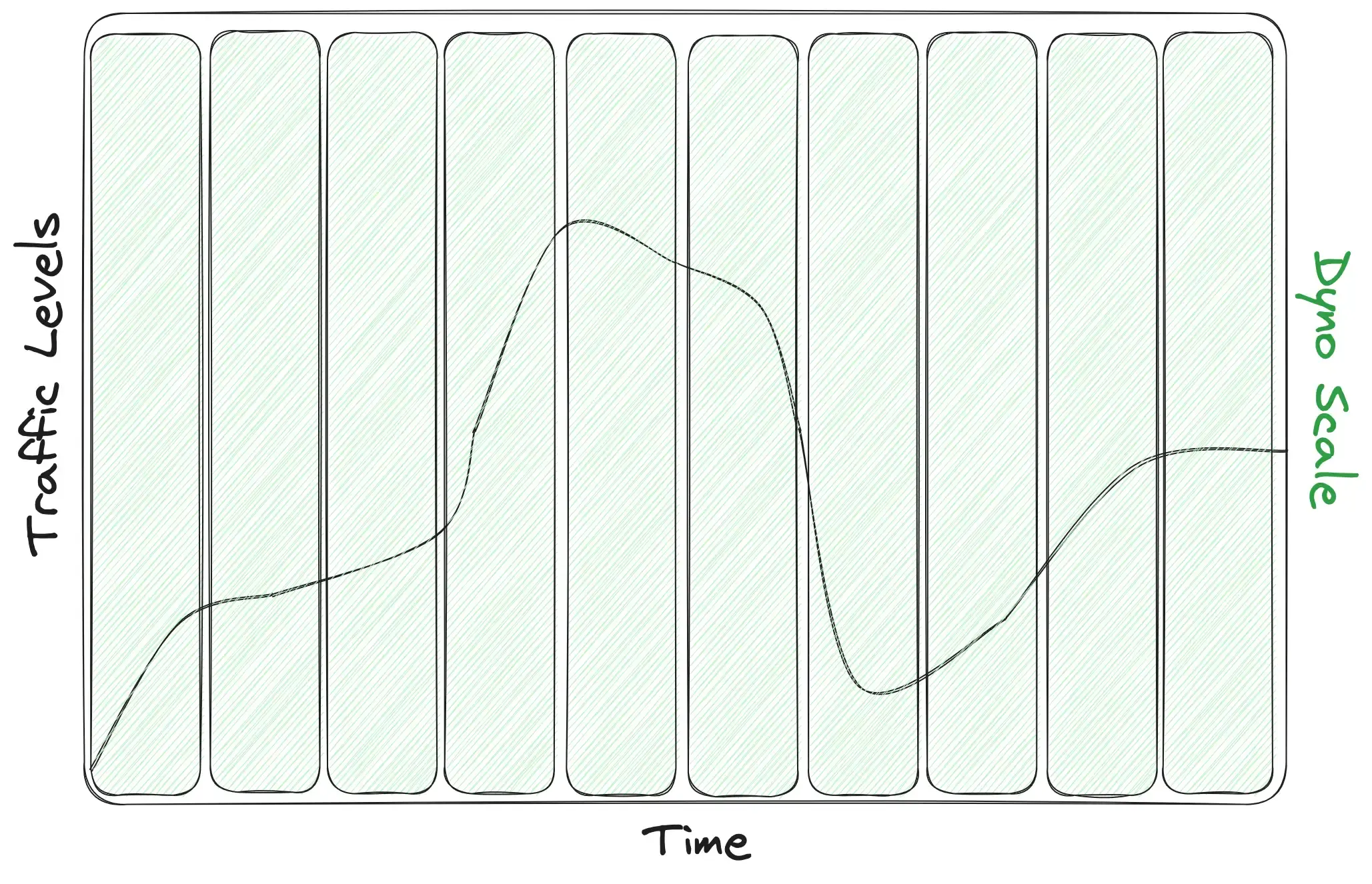
So sure, in that graph we do have enough capacity for all of the traffic over time, but that graph also shows how much capacity (paid with dollars❗️) is wasted over time. If we shade the area above the line red, we can better see how much capacity went unused over the course of this timeline. These dynos had the capacity to serve more requests than they received, but that availability was wasted since traffic simply wasn't that high:
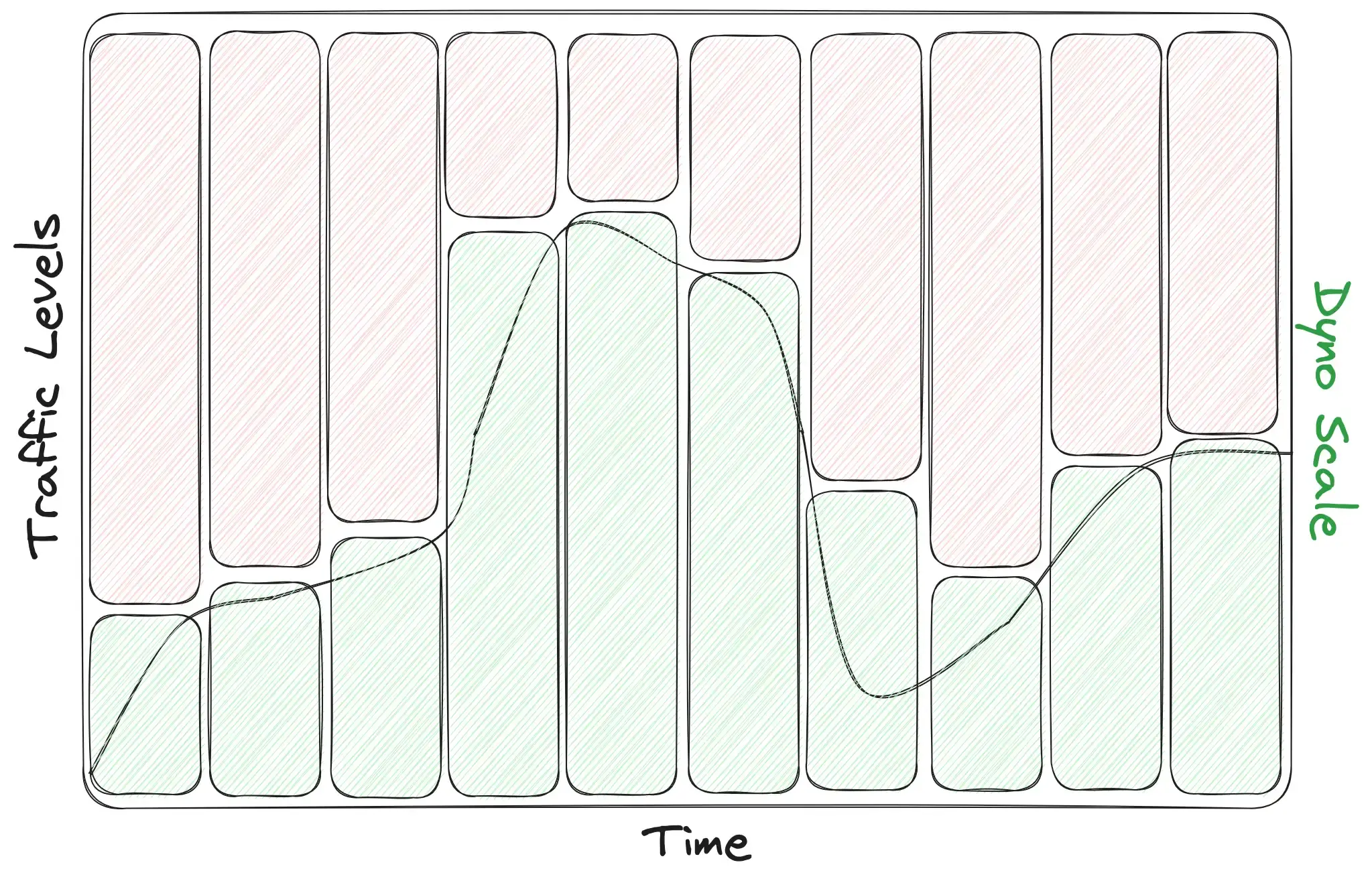
Now this is purely an example graph with no actual units of measure, but that’s probably half of the total hosting bill wasted! That’s what ‘throwing money at it’ is — accepting that fixing a problem with money alone will be more expensive and wasteful than fixing a problem the right way.
So when is throwing money at scaling the right solution? We generally only recommend this as a short-term, stop-gap solution while you work on integrating a better automatic scaling solution, as long as you’ve got the funds to do it safely. Staying at a single scale level, even if high, is a permanent risk.
So what are ‘traffic issues’?
For the purposes of this article, we're using 'traffic issues' to describe any back-end slowness that arises from an increase in either incoming traffic, or downstream bottlenecks (APIs, databases, etc.). Any sort of conditions which would cause your dynos to slow down their service of incoming web requests would be considered 'traffic issues,' though not all traffic issues are equal. Generally, we're after those issues which can be fixed by scaling up the number of dynos in your app.
As a classic example, consider that you kick off 1,000,000 background jobs but only have a single background job dyno running. That's quite a backup — it's going to take a while to churn through those jobs. It'll go much faster if you have a hundred background job dynos! This is a case where your dyno scale can help you.
Conversely, if your app's database is offline for some reason, adding more web dynos will not help you. In fact, if instead your app's database has reached its connection limit (as described briefly above), scaling up your dynos will actually hurt the app! Not all traffic issues can be fixed with scaling your dynos!
What is ‘autoscaling’?
Simply put, autoscaling is the process of automatically determining, and provisioning, the number of dynos for your application based on various factors. It's granting power to a system to answer "how many dynos should we be running right now?" for you — so that you don't have to! Autoscaling is simply "automatic scaling".
This is no different from the classic grocery store metaphor — as the checkout lines grow longer, the store manager opens new checkout lanes and alleviates the lines. In this way, the store manager is the autoscaler, the checkout tellers are the dynos, and the store owner that didn't have to worry about any of this is you, the Heroku App owner! 😁
Option 2: Heroku’s Autoscaling
The second approach we’ll cover is Heroku’s own built-in autoscaler. For starters, Heroku only offers this feature for Perf dynos and for Private/Shield (enterprise-class) customers, and only for web dynos. That cuts out many of the apps running on Heroku, but ironically those apps that are running on perf / private dynos are the ones who should avoid Heroku’s built-in autoscaler the most! Hold that thought.
It’s all about efficiency. Let’s look at our graph again, but make it a little more realistic this time. The first thing to understand is that our green box above is actually several green boxes, each representing an active dyno. And the height of each green box varies depending on which dyno type you’re running: perf-l's can handle a lot more traffic than std-2x's, which can handle nearly double the traffic of std-1x's for most apps:
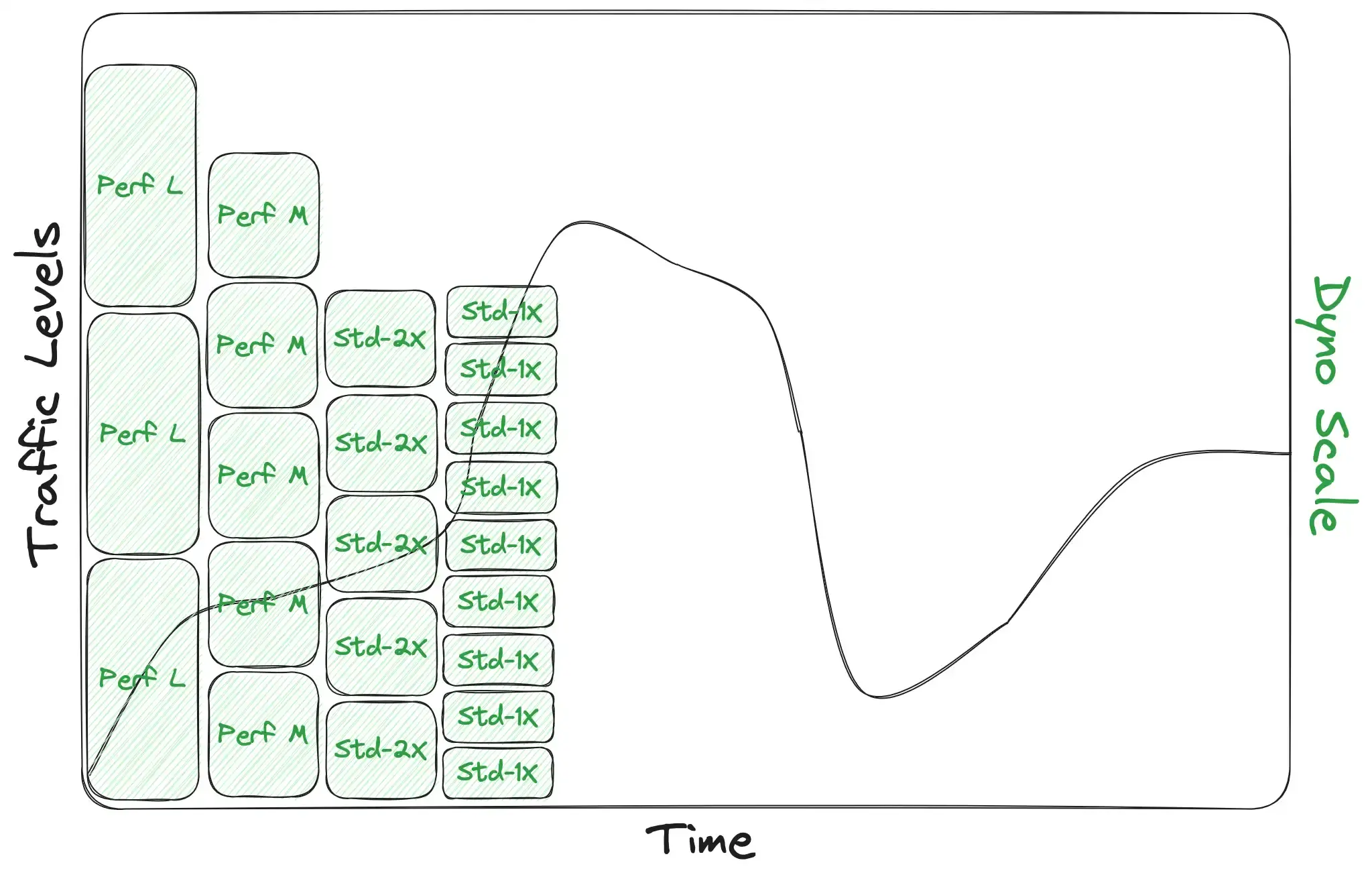
The second thing to understand about this chart is the width of the green boxes. This represents how fast your app can scale up and down according to its traffic levels; how responsive your autoscaling is. Note in this next chart the difference between how tightly the boxes can follow the traffic curve when they’re double-wide (on the left) vs. single-wide (on the right). Wider boxes can’t follow the traffic curve as tightly:
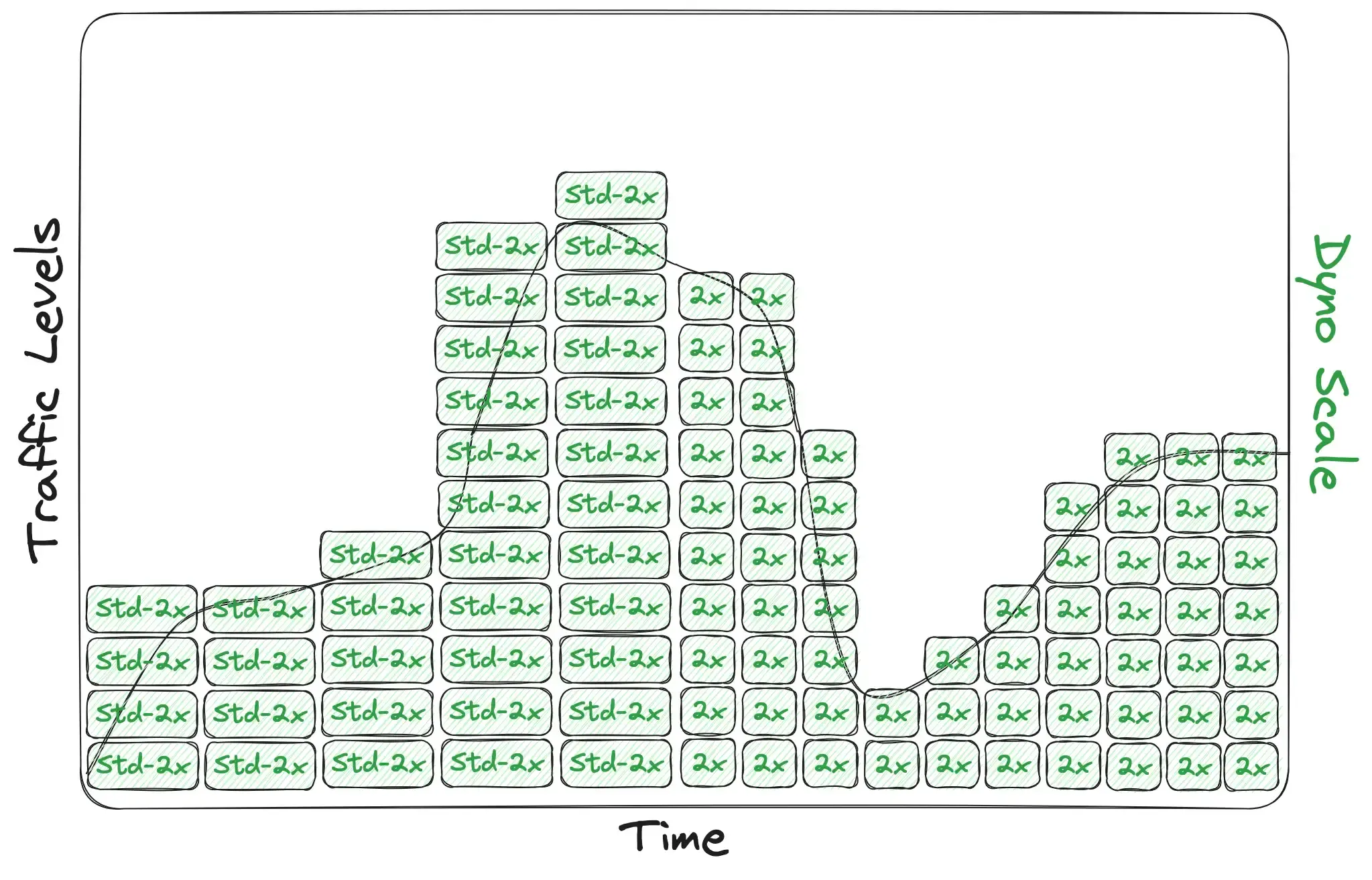
Box heights and widths combine to represent a scaling system’s efficiency: how tight it can cling to your traffic curve. To illustrate this point, here’s an example app using perf-l dynos (tall boxes) and a not-very-responsive autoscaler vs. the same app switching to std-2x dynos and a very responsive autoscaler:
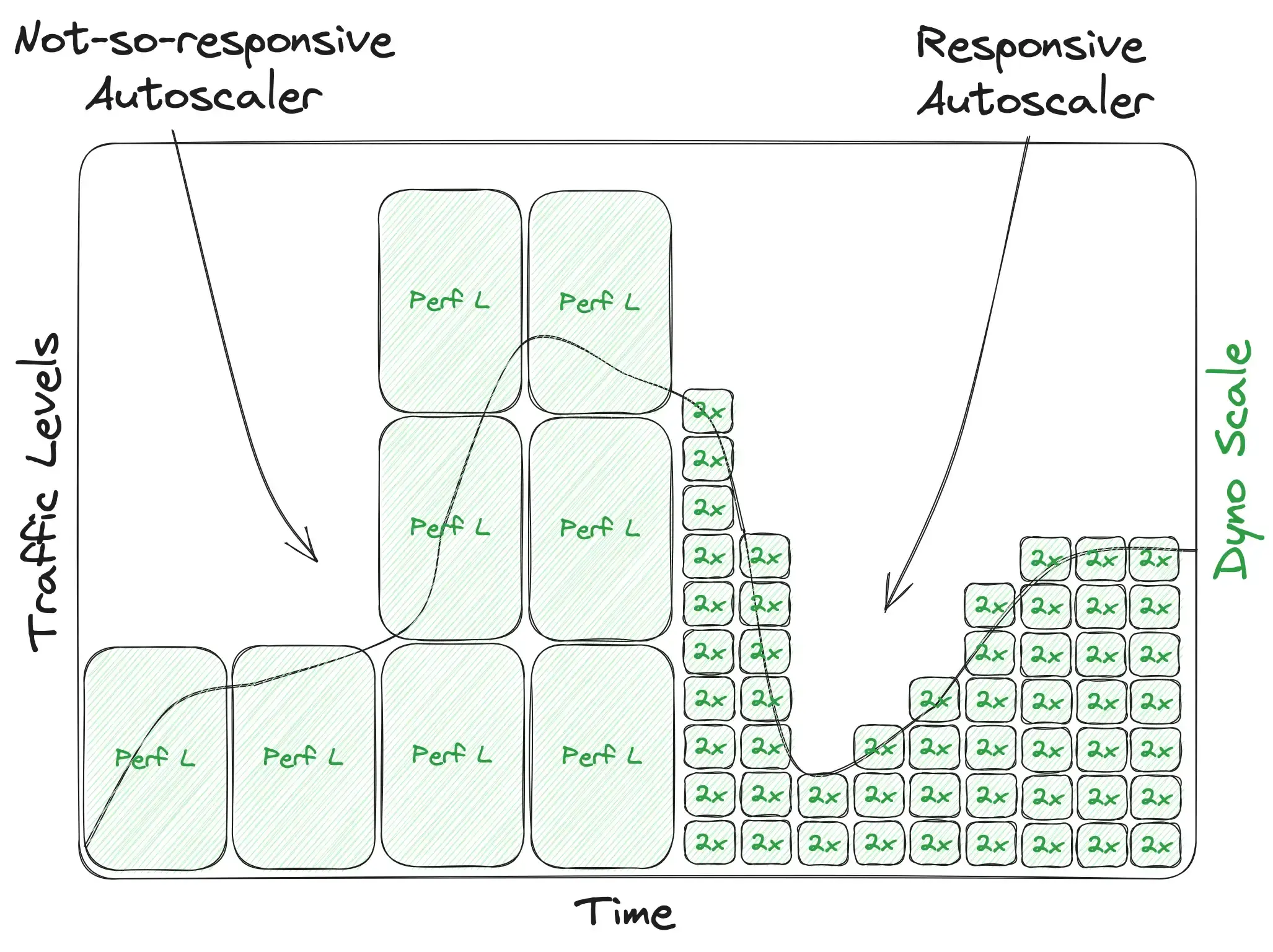
The key point here is the relationship between the scale and the traffic curve. Since you have to pay for every dyno you’re running in real-time regardless of how much it’s actually being utilized, the express goal of an autoscaler should be to keep your scale boxes as close to that curve as possible, but never below it. If the scale were below the line, that'd be the everything's-on-fire issue we started with. Conversely, any scale amount above that curve is wasted money! Let’s zoom in on the very top of the curve above where the app is using perf-l's...
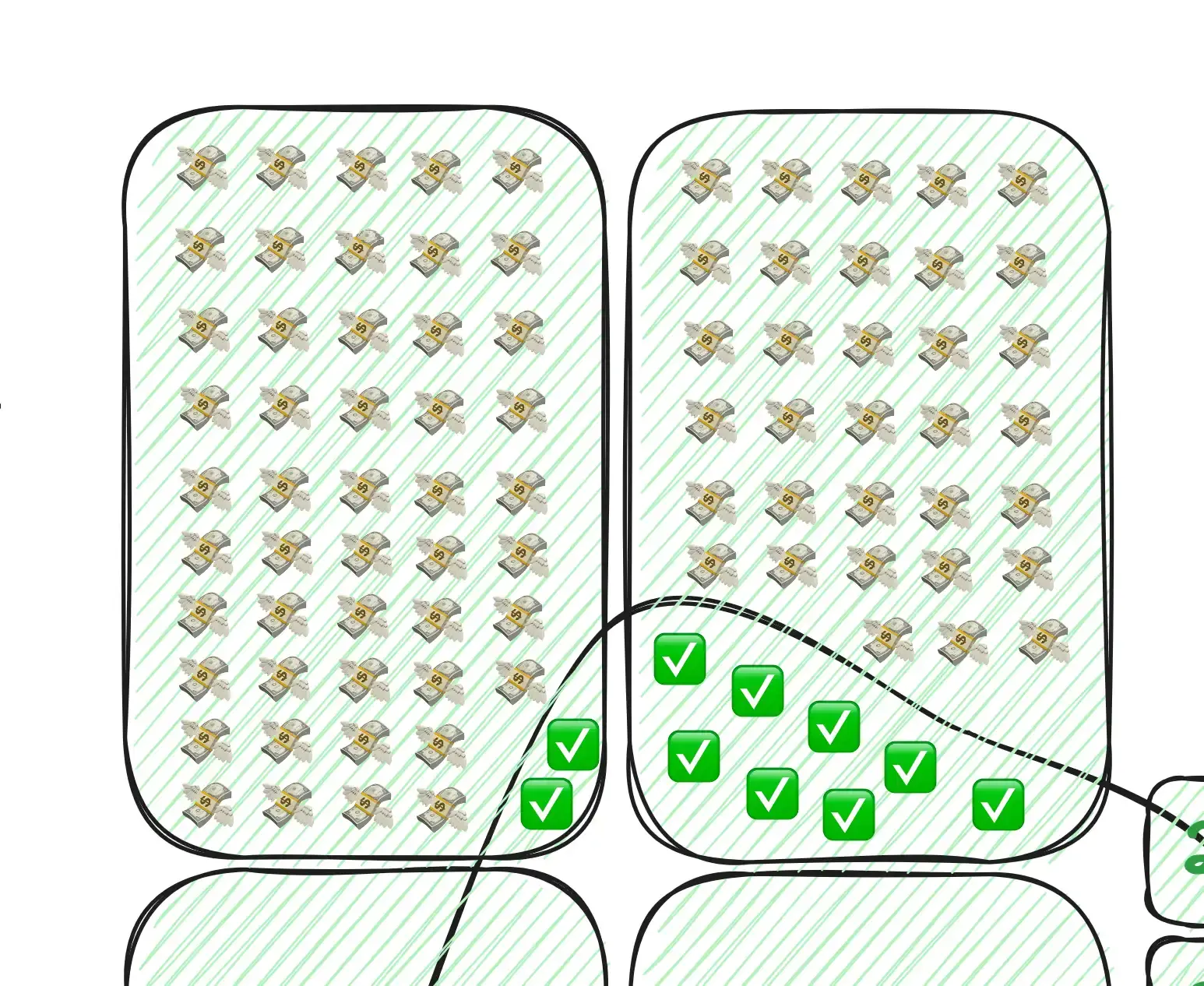
That’s a lot of money just flying away! If that same app and same traffic curve was using a more finite dyno type (shorter boxes) and more responsive autoscaler (skinnier boxes), it might look more like this:
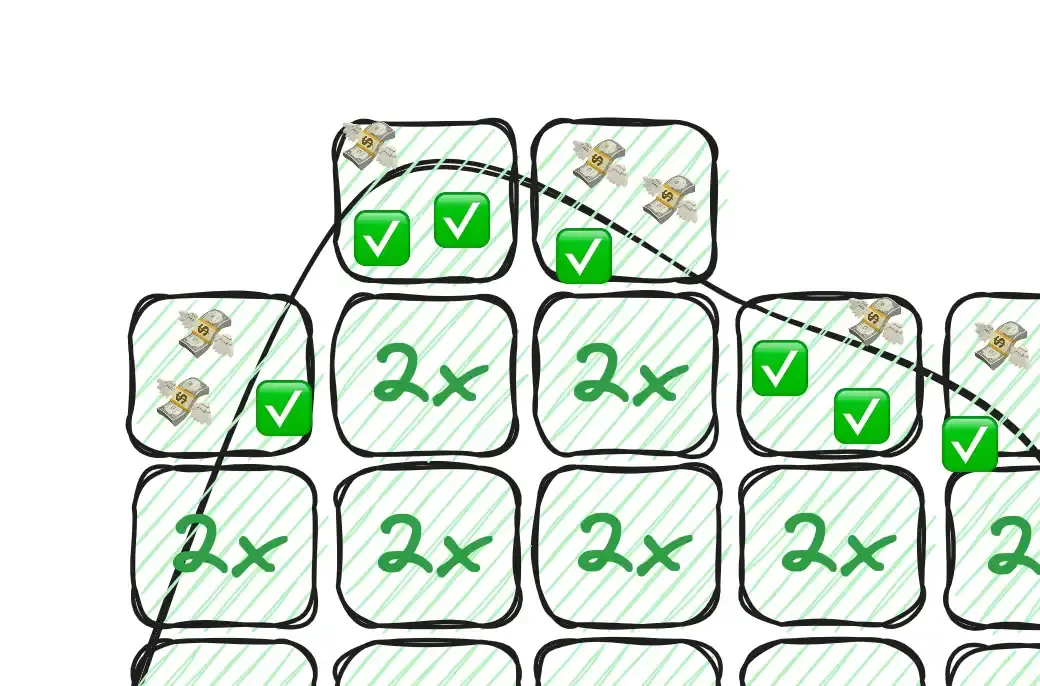
Far fewer monies flying away (so long, monies! 💸).
Back to Heroku’s autoscaler
Circling back from autoscaling efficiency, let’s talk about Heroku’s autoscaler itself. As we mentioned before, Heroku’s autoscaler is a feature reserved only for perf+ dynos, and only for the web process. But unfortunately, it’s also not very responsive, and thus, not very efficient!
There are two factors that contribute to this. First, Heroku autoscales your web dynos based on response time. Second, Heroku’s autoscaling algorithm doesn’t actually trigger scaling very quickly. We’ve written pretty extensively on why queue time is the metric that matters for scaling, not response time, but suffice it to say that scaling based on response time can lead an app with naturally slow endpoints (say, file uploads or API calls) to trick an autoscaler into keeping the app over-provisioned (💸💸). Response-time autoscaling is simply less accurate and less efficient for keeping your app scaled correctly. To our second point, Heroku’s autoscaler simply doesn’t react very quickly. When we’ve run audits on Heroku’s autoscaler, we find that it typically takes multiple minutes to scale up a single dyno in response to response times slowing. That's multiple minutes of requests hanging or failing and probably some alerts in your monitoring tools. Since Heroku's autoscaler only jumps in increments of one dyno at-a-time, that 'multiple minutes' can be painful if your app has large influxes of traffic that require several more boxes to accommodate!

Unfortunately, this means that Heroku's native autoscaling is more like "scale up (slowly) once things are already in trouble" 😬. That said, this option has its pros and cons:
The Pros
- It's already built-in to Heroku and simply requires checking a box to activate
- It’s free... for eligible dynos (which happen to be the most expensive!)
The Cons
- The autoscaling algorithm is based on response time, which isn't ideal
- The autoscaling algorithm runs fairly slowly and could fail to scale fast enough for influxes of traffic
- You cannot schedule any sort of scaling ahead of time
- Autoscaling only works on your
webprocess — no scaling of background jobs or processes - Autoscaling is only available for
perf(or higher) dyno tiers
So when is Heroku's autoscaler the right solution? Unfortunately, given the long list of cons above, we don't ever recommend Heroku's autoscaler as the right solution for any situation. If you're already at a point of pursuing autoscaling, it's both easy and very worth it to go just one step further. That one step is...
Option 3: Autoscaling Add-ons
So, knowing all that we know from the prior two sections, what exactly are we after? Here's the list that comes to mind:
- An autoscaler that's simple to use
- An autoscaler that's very responsive to the traffic curve
- An autoscaler that executes scales quickly to prevent slowness and downtime
- An autoscaler that works on all dyno types that can be scaled
Essentially, we want our dyno scale to cling as tightly to our traffic curve as possible without ever being beneath it. That means both thin bars (responsive autoscaler) and short steps (using a dyno tier where scaling up or down by one dyno represents only a fraction of capacity). Visually, we're after this:
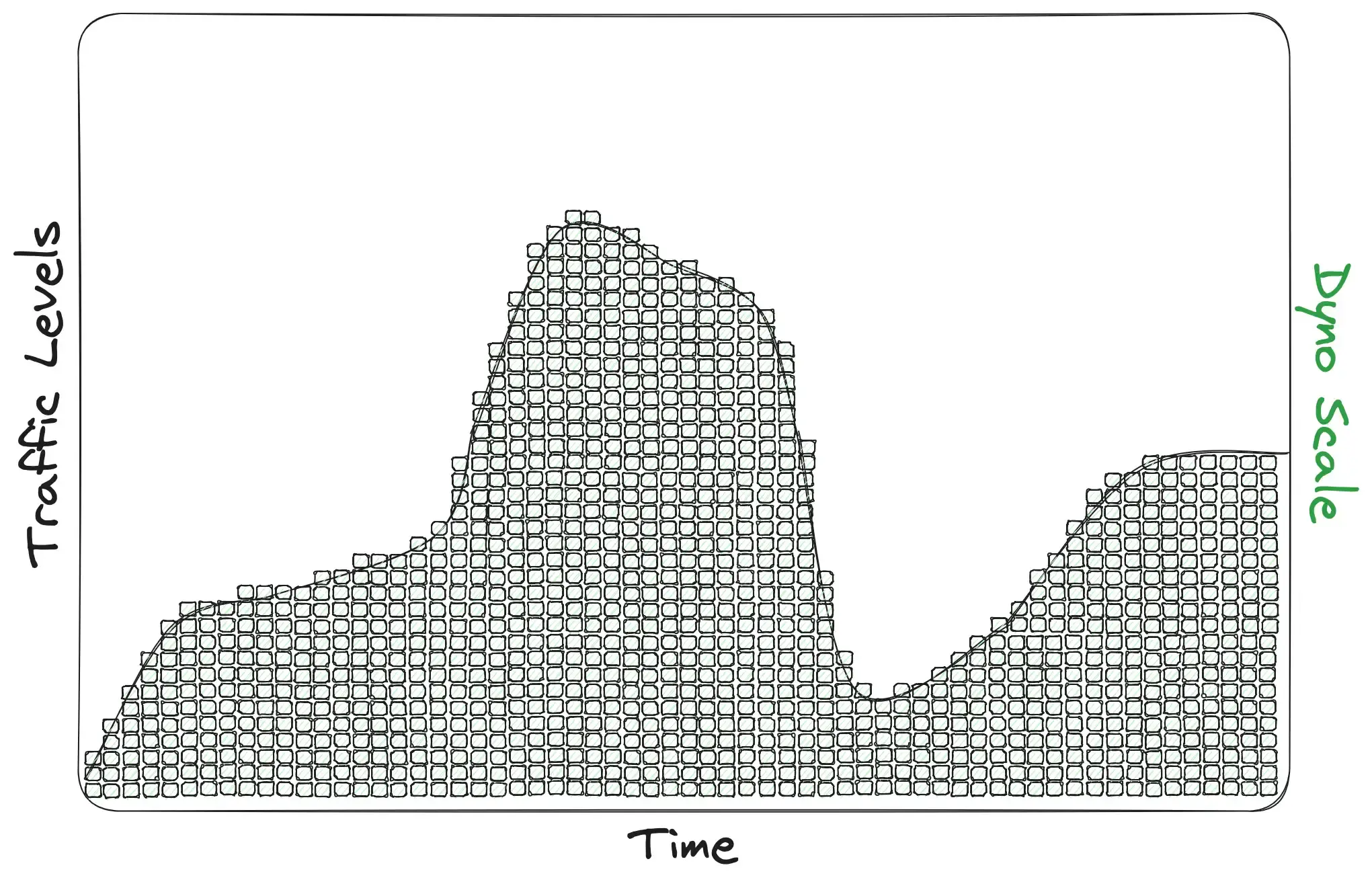
(Keep in mind that this is proportional. If your app is getting thousands of requests per second those little blocks may well be perf-l's. If your app is smaller, those little blocks may be std-1x's. The goal is to keep the blocks small relative to the traffic curve so that a responsive autoscaler can be as modular as possible in scaling!)
We should also be able to use autoscaling in all of our dynos and process types. Which means we want...
Infinite Background Job Volume
Autoscaling in our background processes can totally change the paradigm of our background job system. Under the purview of an efficient autoscaler it transforms into a fully elastic volume processor. Think of it this way: you might only need one dyno running your background jobs day-to-day, but if you suddenly need to process a million complex background tasks, you no longer have to think twice about it! Autoscaling will kick in and spin up as many dynos as it takes to get your queue back under control. From one to one thousand! This is another one might be easier to understand visually:
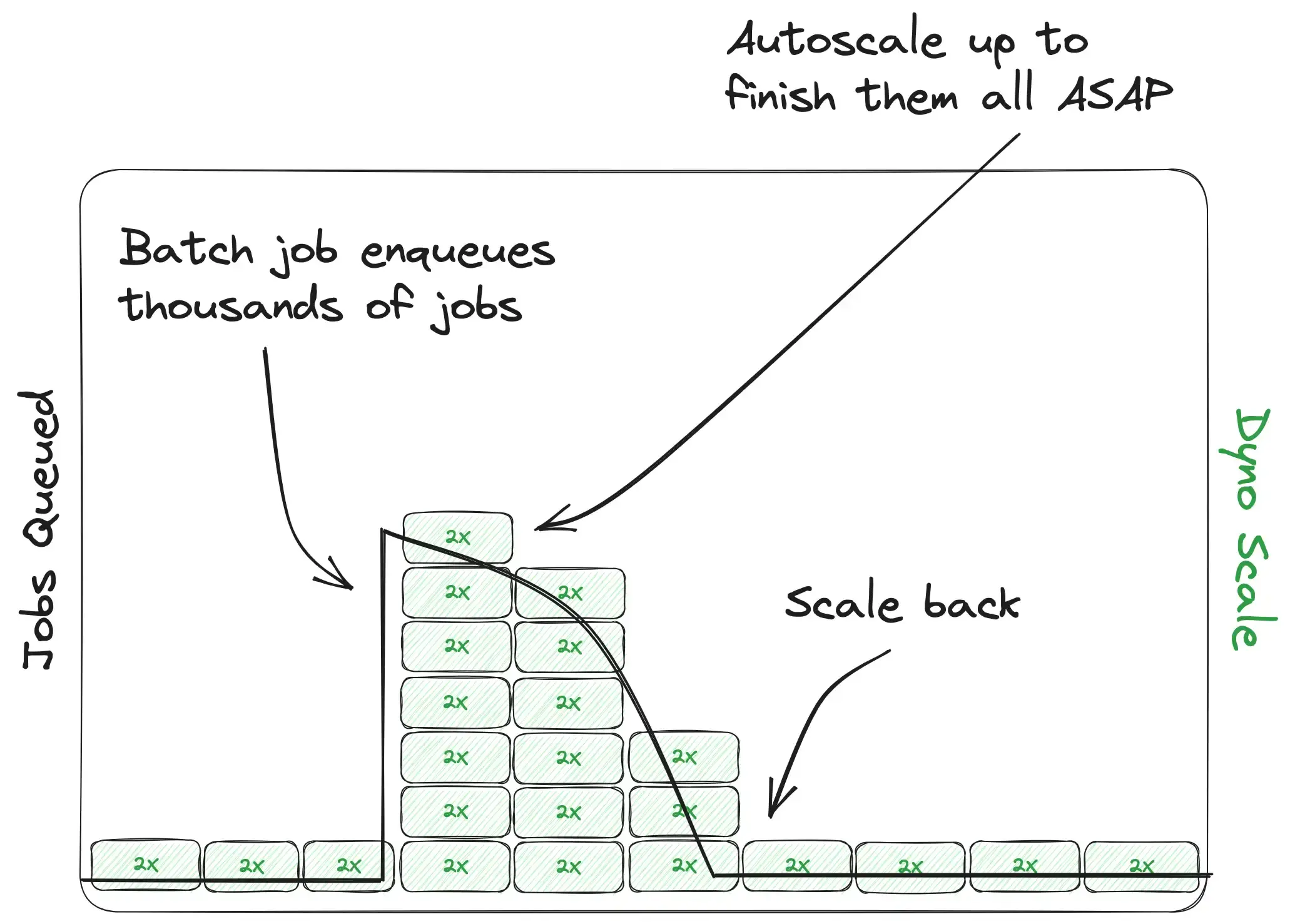
As cool as request and web dyno autoscaling is, background job autoscaling may well be an even more powerful tool for making your app elastic. The amount of raw work that can be accomplished is nearly limitless and allows you to design background jobs and architecture with scale in mind. We definitely want this feature.
Heroku Autoscaling Add-ons can accomplish these things for us.
But Which One?
While the Heroku Add-ons marketplace has several options these days, we believe that Judoscale, our own autoscaling add-on, is still the best-in-class. In fact, it was the desire for all the aforementioned features that lead us to build Judoscale in the first place. Judoscale is simple to use, responds to traffic spikes in 10-20 seconds, scales based on queue time, works on all scalable dyno types, autoscales background job systems, and works with all process types for Ruby applications, NodeJS applications, and Python applications thanks to our custom, open-source packages for each. Feel free to check out our demo app to see what Judoscale looks like in action — no login or info required:
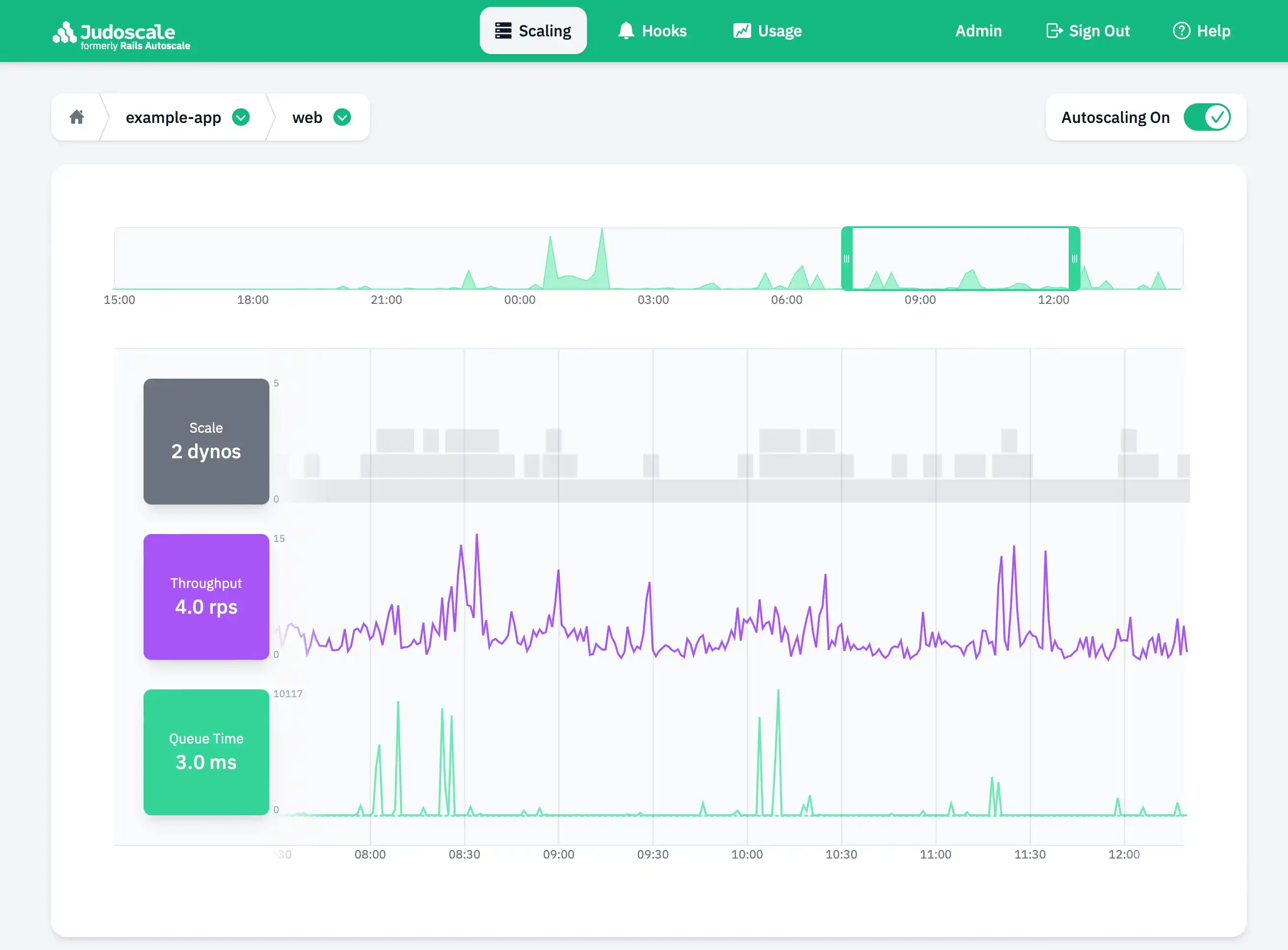
Judoscale-specifics aside, let's assess the pros and cons of using a third party autoscaler instead of Heroku's.
The Pros
- The UI will be designed and tailored specifically for scaling concerns
- It should be more responsive than Heroku's autoscaler (though which add-on you choose will make a difference here)
- It should be quick to scale your app up and down (though again, the specific add-on you choose makes a difference here too)
- It should work on all dyno types and process types
- It should work for background jobs (though some autoscaling addons may not)
The Cons
- They aren't free (but they're usually only a fraction of the cost of your dynos)
- They typically require you to install a package into your app to get the best scaling results
So when is a third-party autoscaler the right solution? Obviously we might be a bit biased here, but we believe that any and every production application should have an autoscaling system and that Judoscale is the best of these. Compared to the costs saved, headaches defended, and traffic capacities freed, it’s a no-brainer. Every production-tier application should get a dedicated autoscaler.
Wrapping it up
So we've got three distinct options for our dyno scale on Heroku: 1) throw money at it, 2) use Heroku's built-in autoscaling, or 3) use an add-on like Judoscale to keep your scale close to your traffic curve.
Any of those three choices is going to benefit your team and application, but each has its own limits and pros/cons that will impact your particular setup. Not all application problems are going to be fixable by scaling (or autoscaling), but many are. We recommend having autoscaling enabled for every production app in the wild and using the monitoring and tooling that comes with an autoscaler to get a better sense of your app’s behaviors and norms.
Autoscaling is a net win for any Heroku application. We should all take advantage of that!
Need help? Have questions? Want to talk about scaling efficiency? Judoscale is a tiny team of two and we read every email that comes our way — no need to be a customer of ours. Give us a shout and we’ll do our best to help you!