Heroku Preboot Gotchas: Read This First

Taurai Mutimutema
@rusIQeMaintaining an engaging app experience involves creating and deploying new features regularly. To achieve this, developers and most software development methodologies have been adopting a continuous integration and deployment (CI/CD) mantra.
As straightforward as the idea of CI/CD sounds, it comes with a few complexities. For instance, integrating new features into a production environment is risky: so much that companies used to schedule and enforce system maintenance service breaks. The result was inevitable downtime that undoubtedly inflicts discomfort on the end-user side.
Clearly, somebody had to come up with an alternative deployment approach. That approach came through as the blue-green method, and that someone was the duo of Dan North and Jez Humble.
What Is Blue-Green Deployment
Over time, developers came up with the blue-green deployment "trick" that mitigated downtime and some errors consistent with seeking CI/CD. In a nutshell, a green environment would replace a live blue doppelgänger setup, implementing fresh features in the process.
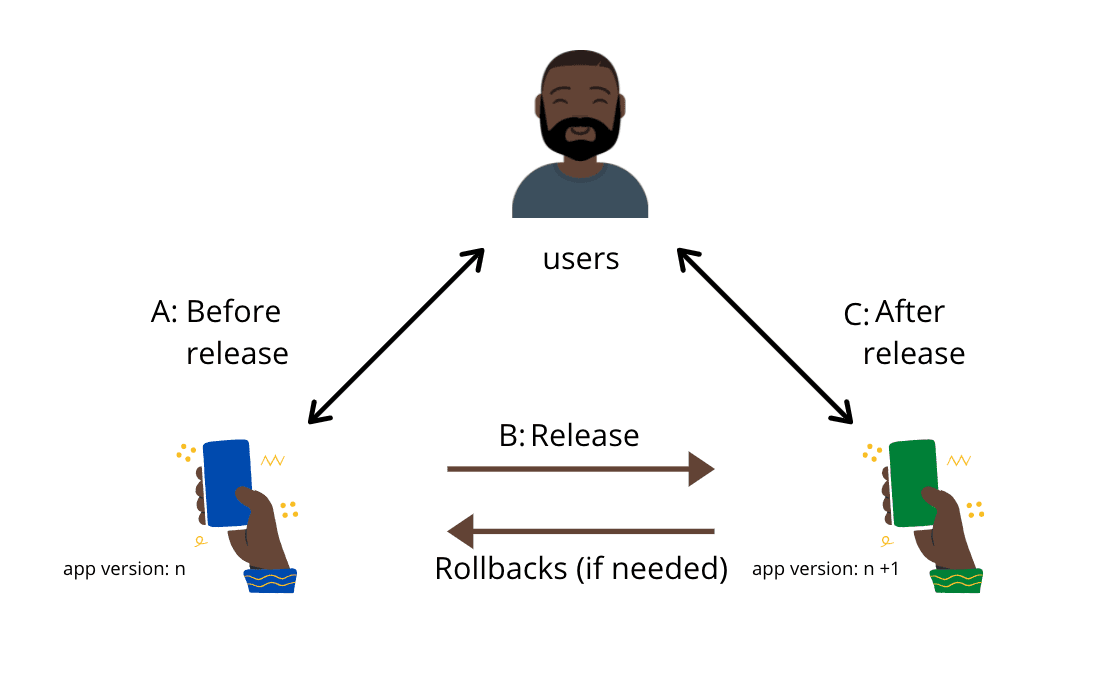
Key:
A - The old connection between users and your app
B - The blue app's environment transitions to green
C - New connection between users and the green environment
The transition phase has to happen over some time, during which both B and C are live and accessible to users. We'll go into detail about this duality in a bit. For now, let's discuss why blue-green is a worthwhile deployment strategy.
Advantages of Blue-Green Deployments
There are plenty of reasons why blue-green is a better deployment method than the old break service route.
1. Easy rollbacks. Since you're replacing a functional (blue) environment, any fatal errors that might slip through your testing are easy to undo. As long as you don't immediately delete the original environment, it would be a matter of redirecting traffic back to the old app version.
2. Maintains app uptime. This factor is in comparison to the old approach of shutting everything down before affecting new features. The blue-green deployment method's best upside is how users maintain connections to services.
Disadvantages of the Blue-Green Approach
While it has some interesting benefits, the blue-green deployment approach is not without its thorns.
1. It can get expensive. The concept of running identical resource environments piles costs on your account. Even when done onsite, you may have to procure hardware and spend on technical assistance to get things done.
2. Database handling complexities. Every database schema change must be made to work simultaneously with the blue and green app versions. Typically this means that schema changes require at least two separate deployments—one for the schema change, and one for the application change.
3. Performance lags. Moving from one environment to another can cause dips in application performance. This cold switch often purges performance assets that take time to build (think of cache here). Although this was always the case before CI/CD came in fashion, the blue-green method on its own does very little to suppress it.
4. Unfinished requests. At the very second that you switch environments, chances are every user trying to run requests will be interrupted. Unless you build some continuity into your app, they'd have to be logged out and asked to redo every task they had previously attempted.
For Heroku-hosted applications, the blue-green deployment method would then be implemented using two sets of web dynos. Interruption is mitigated by directing traffic away from the blue dynos while they are shutting down but allowing them to finish existing requests. Heroku handles this by giving dynos thirty seconds to shut down.
Note how the usual Heroku dyno start behavior immediately sends traffic to fresh dynos, even while they are still booting and unable to handle requests. This is perceived as downtime. The newly started instance takes time to "warm-up" and perform at comparable levels to its predecessor.
Enter Heroku Preboot
Accessible in the standard dyno as well as the performance dyno types, Preboot makes possible that dual environment essential for blue-green deployment. Let's explore how this change in dyno start behavior works.
Preboot hinges on the fact that each time you make changes to your app in production, Heroku initiates a release process (it boots a new version before the old one is shut down) for integration. As soon as the new build concludes, a new dyno is created automatically as a new version of the app. This way, the app appears to be online on the frontend regardless of the interchange of the two different versions.
At this point, you will have created an ephemeral blue-green scenario. In approximately three minutes, the traffic that was heading toward the old dynos are routed toward the newly formed replacements.
The process concludes when all services are accessible and the new dynos are stable, at which point the old ones are terminated. As you may have gathered already, there are pros and cons to this process.
The Benefits of Continuous Deployment with Preboot
There are two main advantages of preboot:
1. Preboot is efficient. The automated creation of dynos cuts a lot of time off the budget that is otherwise set aside for handling downtime.
2. It provides better application environment starts. Diverting traffic to new environments removes the performance dip issue consistent with starting a dyno and pushing traffic toward it at the same time.
The Gotchas of Preboot
Watch out for the following less-than-desirable outcomes when working with preboot.
1. Database migrations are more complicated. Synchronizing database schema alterations to facilitate the dual environment usage phase can be tricky. While this is subject to the complexity of your app, even having different database copies makes for further complexity. Preboot essentially leaves this part in your care.
2. Dual service window. In theory, Heroku stops the old dynos as soon as the new ones are primed for traffic. However, there's a small gap during which you actually have services emanating from both environments. This doubles the number of concurrent connections, and could cause issues at the database layer if the connection limit is insufficient.
3. Lack of control. When using Preboot, you're completely reliant on Heroku to make the routing switch to the new dynos. This happens roughly three minutes after a deploy, and you can't change this, nor do you have any visibility into whether or not the switch has taken place.
The Take Home
Clearly, there's a trade-off of complexity vs. momentary slowness when using Preboot to handle continuous deployment in Heroku. Ultimately it depends on what's most important to your team—simplicity and control, or maximum uptime.