Learn More
Long-Running Background Jobs
Issues with long-running jobs
Anytime a worker process is shut down — due to autoscaling, a deploy, or a daily restart on Heroku — background jobs are at risk of being terminated.
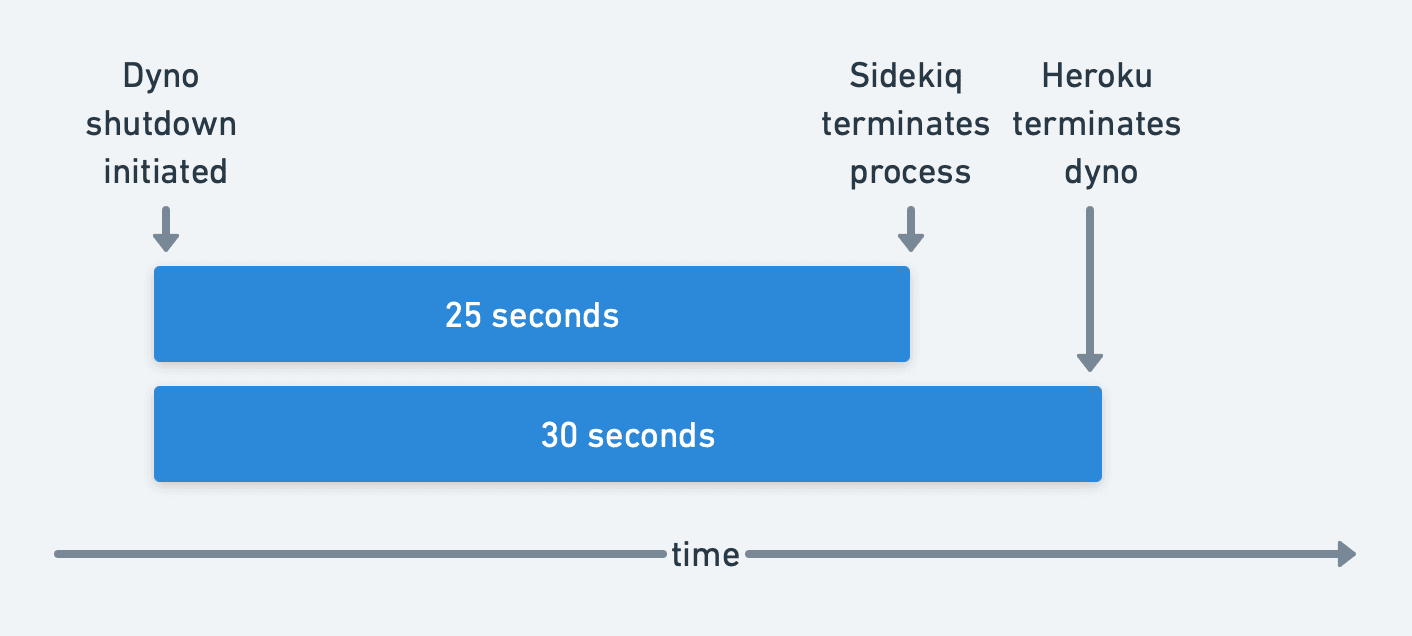
When Heroku shuts down a dyno or Render shuts down a service, processes are given 30 seconds to shut down cleanly. After that, they are forcefully terminated.
A good practice to follow is to make background jobs idempotent and transactional, so that if they are prematurely terminated, they can safely re-run. This is good advice for all job backends since workers can be rebooted at any time.
Sidekiq (Ruby)
Sidekiq handles shutdowns gracefully in most cases. During this shutdown period, Sidekiq stops accepting new work and allows jobs 25 seconds to complete before being forcefully terminated and re-enqueueing in-flight jobs.
Sidekiq recommends making jobs idempotent and transactional to avoid unexpected outcomes when workers are shut down halfway through processing a job.
Celery (Python)
Celery's shutdown process gracefully shuts down workers upon receiving the shutdown signal. It stops accepting new work and gives jobs 30 seconds to complete before being forcefully terminated.
Caveat: Heroku sends a SIGTERM to all processes on the dyno, not just the Celery main process. The net effect is that workers shut down immediately upon receiving the shutdown signal and the Celery main process won't get a chance to re-enqueue in-flight jobs. Heroku recommends remapping the shutdown signal and enabling late acknowledgment of jobs.
RQ (Python)
RQ's shutdown process is similar to Celery's. It gracefully shuts down workers upon receiving the shutdown signal. It stops accepting new work and waits for jobs to complete. It forcefully shuts down upon receiving the shutdown signal for the second time.
Caveat: Heroku sends a SIGTERM to all processes on the dyno, not just the RQ main process. The net effect is that workers shut down immediately upon receiving the shutdown signal and the RQ main process won't get a chance to re-enqueue in-flight jobs. RQ recommends using HerokuWorker on Heroku which handles signals differently and prevents workers from exiting immediately upon receiving the first shutdown signal.
Handling long-running jobs with Judoscale
If we’re following best practices, we’ll have no issues with long-running jobs and autoscaling workers. Our apps are imperfect, though, so we may find ourselves with long-running jobs that cannot be safely terminated and re-run.
Judoscale provides a mechanism to avoid downscaling your worker dynos if any jobs are currently running.
Sidekiq (Ruby)
First, ensure you’re on the latest adapter version, then:
Add the following option to your initializer file:
config.sidekiq.track_busy_jobs = true
This tells the Judoscale adapter to report the number of “busy” workers (actively running jobs) for each queue.
Celery (Python)
First, ensure you’re on the latest adapter version, then:
Turn on tracking busy jobs when you initialise the Celery integration:
judoscale_celery(celery_app, extra_config={"CELERY": {"TRACK_BUSY_JOBS": True}})
RQ (Python)
First, ensure you’re on the latest adapter version, then:
Turn on tracking busy jobs when you initialise the RQ integration:
judoscale_rq(redis, extra_config={"RQ": {"TRACK_BUSY_JOBS": True}})
Enable Long-Running Job Support in the Dashboard
Once these metrics are being collected, you’ll see a new advanced setting in the Judoscale dashboard:
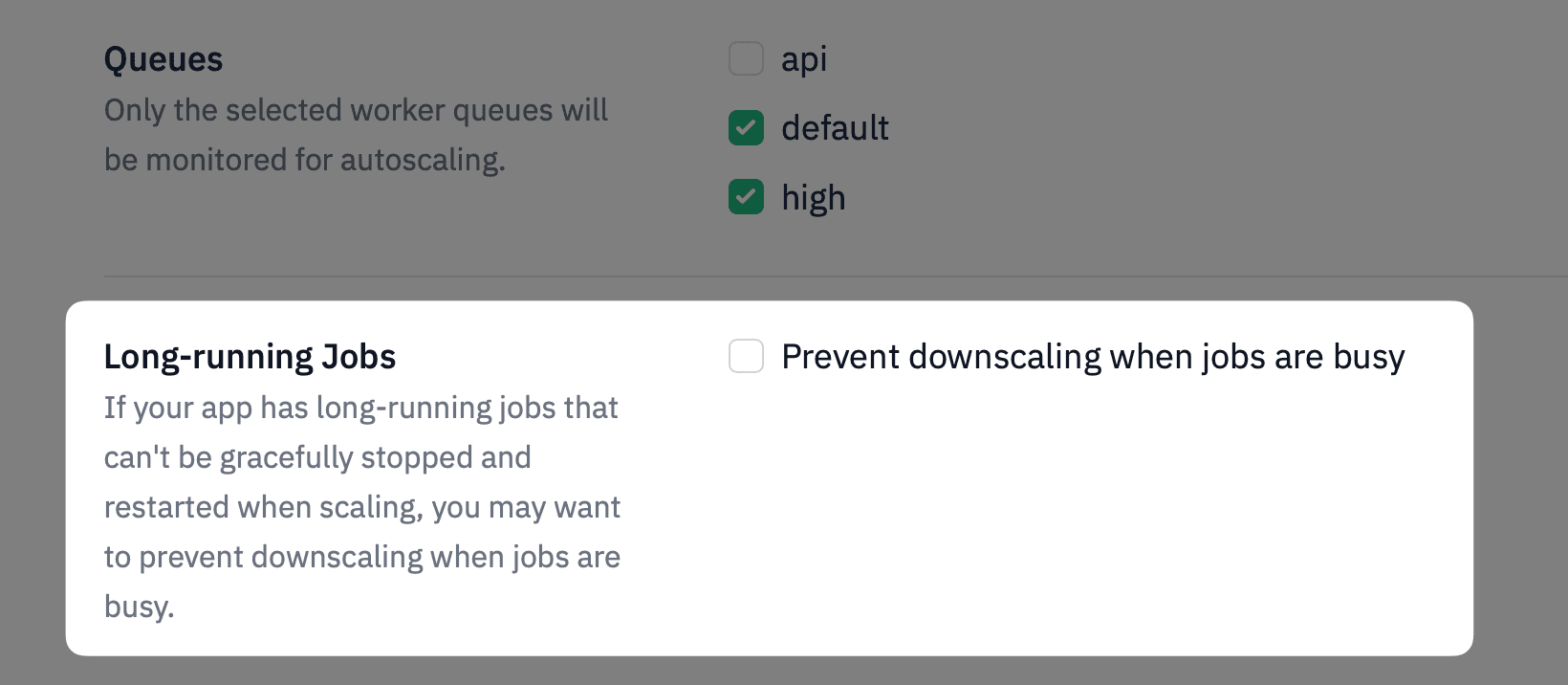
Check this option, and you’re good to go! Judoscale will suppress downscaling if there are any busy workers (running jobs) for the relevant queues.
Be careful, though. If you have fairly constant job activity, your workers will never have a chance to downscale. 😬 This feature is intended for queues with sporadic, long-running jobs.
Caveats
Judoscale can't prevent downscaling completely during active jobs. The track_busy_jobs option reports this data every 10 seconds, so it's possible a long-running job is started between the time data is reported and the time autoscaling is triggered.
Also, this optional configuration mitigates the issues of automatic downscaling killing long-running jobs, but be aware that long-running jobs are still an issue. Deploys and restarts will still potentially terminate your long-running jobs, so if you’re able, you should break up your large jobs into batches of small jobs.