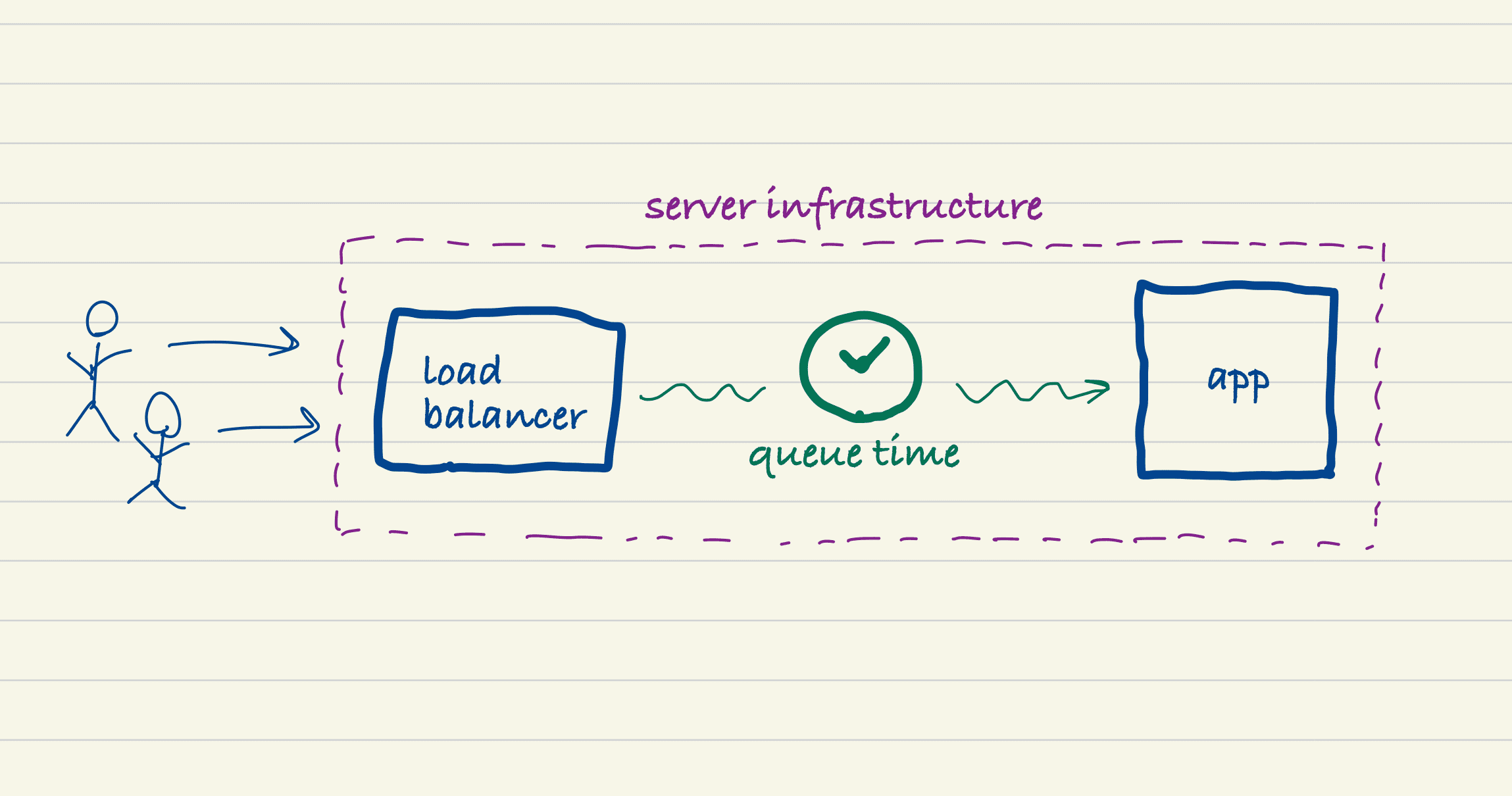
What is this thing?
DB Connections Calculator is a tool for calculating how many potential database connections your Heroku app needs to have available in Postgres. It’s common to encounter connection errors on Heroku, especially in the cheaper Heroku Postgres plans because the connection limit is so low. If you’ve ever seen PG::ConnectionBad: remaining connection slots are reserved for non-replication superuser connections, then this tool is for you.
When you run multiple dynos with multiple processes, connection counts can add up quickly. This tool helps you calculate and visualize those connections so you can choose the correct Postgres plan or adjust your app configuration to fit within your current Postgres plan.
How do I use it?
For each of your running process types (such as “web” and “worker”), drag the sliders according to your current configuration. Additional detail on each of the configurations—how to find the correct value in your app—is provided below.
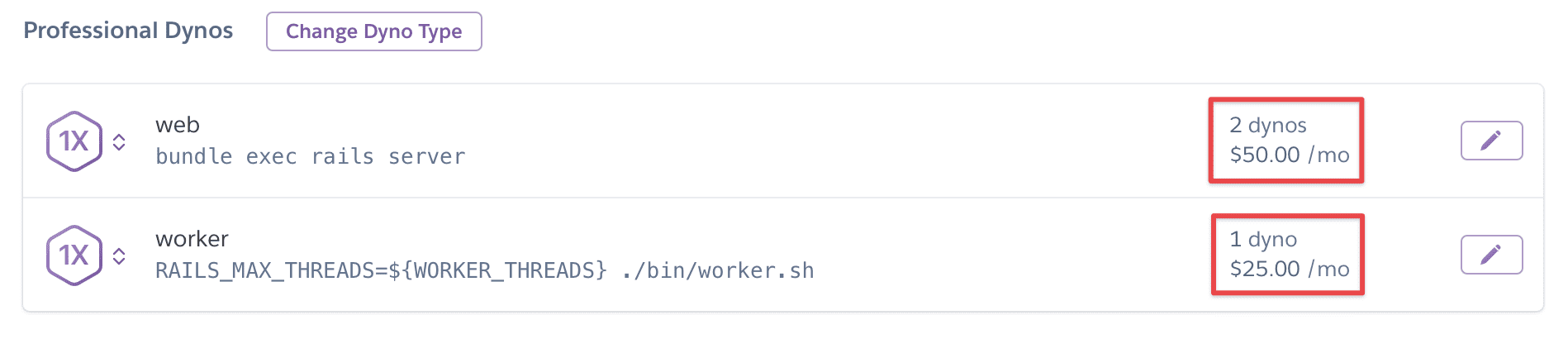
Dynos
You can see the number of running dynos by running heroku ps or in your Heroku dashboard.
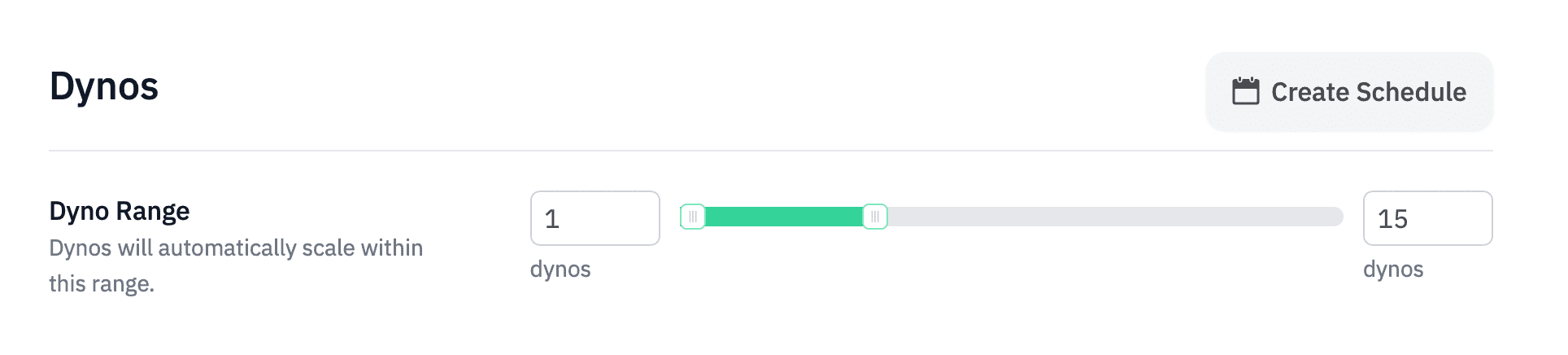
If you’re using an autoscaling add-on such as Judoscale, make sure you use the maximum scale in your configured autoscale range.
Processes
It’s common to run multiple Puma or Unicorn processes (sometimes called “workers”) within web dynos. You can likewise run multiple multiple Sidekiq, Resque, or Delayed Job processes in worker dynos. Running multiple processes lets you utilize multiple CPU cores for parallel processing.
For Puma, check the workers line in your puma.rb file. If this line is commented out, you’re running a single process.

If it refers to the WEB_CONCURRENCY environment variable, run heroku config:get WEB_CONCURRENCY or click “reveal config vars” in your Heroku settings page.

For Sidekiq, you can only run multiple processes with the sidekiqswarm command found in Sidekiq Enterprise. If you’re not using Sidekiq Enterprise, then you’re almost certainly only running a single Sidekiq process. Note that your Sidekiq concurrency setting configures threads, not processes.
Threads
This likely comes from your RAILS_MAX_THREADS environment variable, but you’ll need to check your code to be sure. For Puma, check the threads line in your puma.rb file.

For Sidekiq, your “concurrency” setting is the thread count. If you haven’t otherwise specified a concurrency setting in a sidekiq.yml or -c command line option, then this is also driven by RAILS_MAX_THREADS.

Threads and connection pools
Note that you generally want your thread count to equal your database pool size. When you have more threads than pooled database connections, threads will need to wait for an available connection. This increases response time and sometimes raises ActiveRecord::ConnectionTimeoutError exceptions.
Your thread count will only impact your total database connections if it is smaller than your database pool (and there’s rarely a good reason to do so).
Database pool
Every Rails process has it’s own database pool, which is shared by all threads in that process. This is configured via pool in your database.yml file.
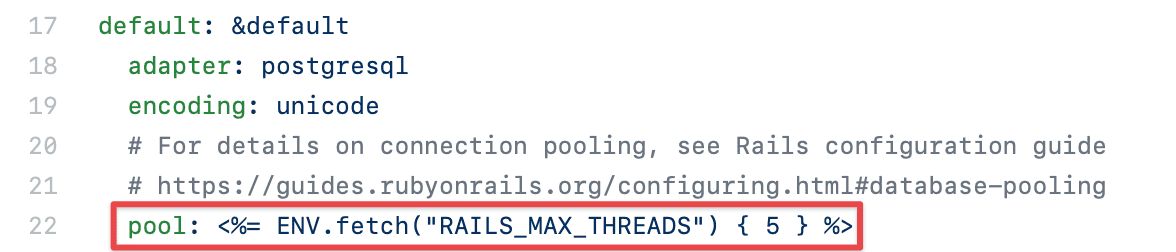
By default it will use the RAILS_MAX_THREADS environment variable, so run heroku config:get RAILS_MAX_THREADS or view your settings page.
It’s also possible to override this environment variable (or any environment variable) in your Procfile or other executable. For example, I recommend customizing RAILS_MAX_THREADS for worker dynos like this:
worker: RAILS_MAX_THREADS=${WORKER_THREADS} bundle exec sidekiq
This lets you configure database pools for web and worker dynos independently. If you’re doing something like this, you’ll need to get the WORKER_THREADS config var (or whatever you’ve named it) for your “workers” pool configuration.
Preboot
Heroku’s Preboot feature allows zero-downtime deploys (rolling deploys) by running two simultaneous versions of your web dynos for several minutes. Traffic is switched from the old dynos to the new dynos once the new dynos are ready to handle requests.
During this short period, you’re running double the number of web dynos, so your web dynos can require up to twice as many database connections. Checking the “Preboot” box will double the number of potential connections from your web dynos.
Total database connections
This number represents the total possible connections with this configuration. Since database connections are created lazily, you might never actually use this many connections, but your database should support that scenario.
Also consider other sources of database connections:
- One-off dynos. When you use the
heroku runcommand, you’re create a new “one-off” dyno for as long as your command runs. This command might create new connections not factored into the calculator. - Migrations. If you run database migrations in a release phase, this happens on a one-off dyno and will create connections not factored into the calculator.
- Scheduled tasks. If you use a scheduled task runner like Heroku Scheduler, this also uses one-off dynos.
- Third-party tools. Do you connect to your database from third-party reporting or monitoring tools? Consider those connections as well.
PGBouncer
Large-scale applications often find themselves needing more than 500 database connections, which is the highest limit of any Heroku Postgres plan. In this scenario it makes sense to use PGBouncer, which is a server-side connection pool for Postgres and is supported natively by Heroku.
Rather than connecting directly to the database, your application will connect to PGBouncer, which runs on the Postgres server. PGBouncer connects to the database, and it will never use more than 75% of the database limit.
For example, if your Postgres limit is 400 connections, PGBouncer will establish up to 300 connections to Postgres. You can create up to 10,000 connections to PGBouncer, and PGBouncer manages access to the pool of 300 database connections.
Read more on connection pooling for Heroku Postgres.
Feedback?
Email me or find me on Twitter. 👋
and never worry about your dynos again